

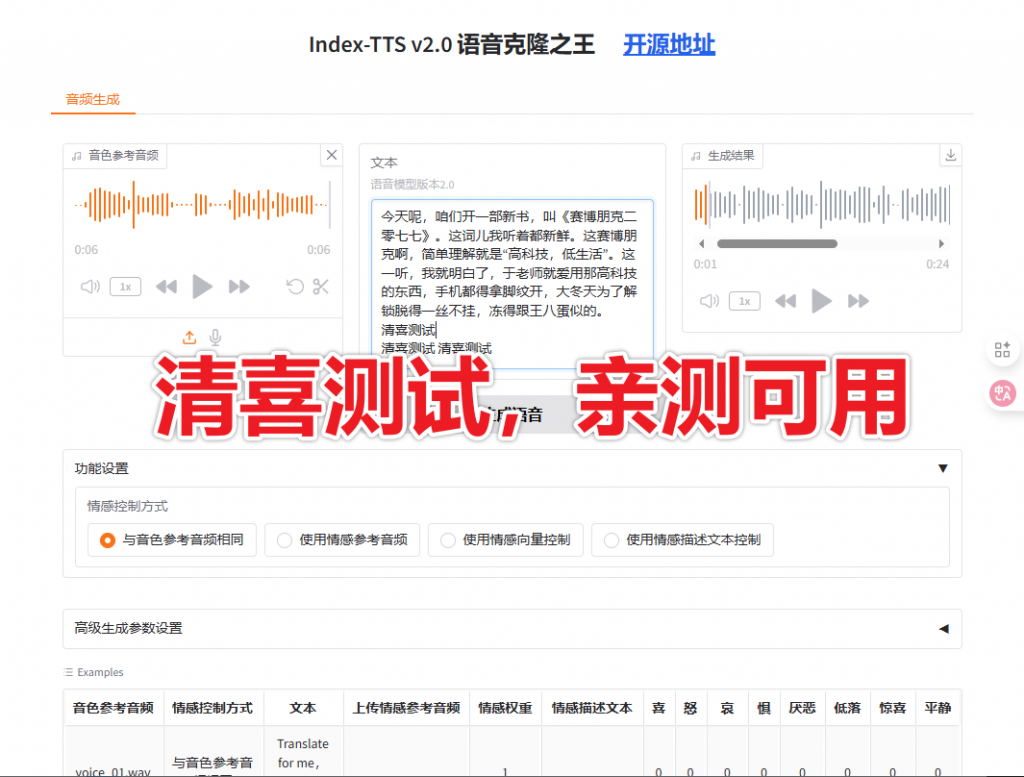
B站的IndexTTS-2声音克隆模型在前几天终于发布了,支持多种情感控制,可以使用相同音色、其他参考音频、情感向量,或者直接使用文本描述,其中好多的群友在问我,我给大家安排上这一份工具,来源于蒙恩大佬分享给我的。纯离线免费使用。

软件特点
1、两种语音生成模式
精准控制语音时长:通过指定生成的 token 数,满足对时长有严格要求的场景。
自由生成自然节奏的语音:适用于更注重自然表达的应用。
2、情感与音色解耦
引入 Gradient Reversal Layer:进行情感 – 音色的解耦,使得情感表达不再受限于音色。
多方式情感表达控制:支持使用文本描述或音频 prompt 控制情感表达,大大提升了情感表达的灵活性。
3、零样本音色克隆
仅需10秒参考音频,通过对比学习对齐潜在空间,支持方言/口音复刻
中文混合建模:汉字+拼音联合输入,解决多音字问题(如“行”xíng/háng)
4、自然语言情感控制
构建情感 embedding 空间:构建 7 种基本情绪的 embedding 空间,为情感的精准表达提供基础。
LLM 情感映射:使用 LLM(DeepSeekR1 + Qwen3-LoRA)将自然语言映射为情感向量引导生成,让情感表达更加贴近人类语言习惯。
工具截图







还没有评论,来说两句吧...